Bottom-Up Accumulation#
We’ve covered lots of ways to play with the structure of a tree, but, similarly to how we often accumulate values in an array with a reduction, we often want to accumulate the values in a tree somehow, while respecting its structure. Usually, this involves working our way up from the bottom of the tree, with each parent combining the results of its children, until we reach the root.
To show this process, let’s reconstruct the nested representation of a tree, which we saw earlier, from a parent vector.
Let’s look again at a familiar tree.
p←0 0 1 2 2 1 0 6 7 7 7 0 ⍝ parent vector
v←,¨'abcdefghijkl' ⍝ some associated data
v PPV p
┌─────────────┐ │ a │ │ ┌───┴─┬───┐│ │ b g l│ │ ┌┴─┐ │ │ │ c f h │ │┌┴┐ ┌─┼─┐ │ │d e i j k │ └─────────────┘
Our goal is to reconstruct the nested representation of this tree.
(,'a') ((,'b') ((,'c') (,⊂,'d') (,⊂,'e')) (,⊂,'f')) ((,'g') ((,'h') (,⊂,'i') (,⊂,'j') (,⊂,'k'))) (,⊂,'l')
┌─┬───────────────────┬───────────────────┬───┐ │a│┌─┬───────────┬───┐│┌─┬───────────────┐│┌─┐│ │ ││b│┌─┬───┬───┐│┌─┐│││g│┌─┬───┬───┬───┐│││l││ │ ││ ││c│┌─┐│┌─┐│││f││││ ││h│┌─┐│┌─┐│┌─┐│││└─┘│ │ ││ ││ ││d│││e│││└─┘│││ ││ ││i│││j│││k││││ │ │ ││ ││ │└─┘│└─┘││ │││ ││ │└─┘│└─┘│└─┘│││ │ │ ││ │└─┴───┴───┘│ │││ │└─┴───┴───┴───┘││ │ │ │└─┴───────────┴───┘│└─┴───────────────┘│ │ └─┴───────────────────┴───────────────────┴───┘
Something to note is that for leaf nodes, we have almost nothing to do. We can just wrap up the value of the node and we are done.
,⊂,'d' ⍝ the nested representation of node d
┌─┐ │d│ └─┘
We can represent non-leaf nodes by attaching the representations of all their children.
(,'c') (,⊂,'d') (,⊂,'e')
⍝ └────┴─│──────│─│──────│─── representation of the parent
⍝ └──────┴─┴──────┴─── representations of the children
┌─┬───┬───┐ │c│┌─┐│┌─┐│ │ ││d│││e││ │ │└─┘│└─┘│ └─┴───┴───┘
If we continue this process for all nodes, we will cover the whole tree. Since we’re working from the bottom up, we want to start with nodes at the greatest depth, then proceed to the depths of their parents, then their grandparents, and so on.
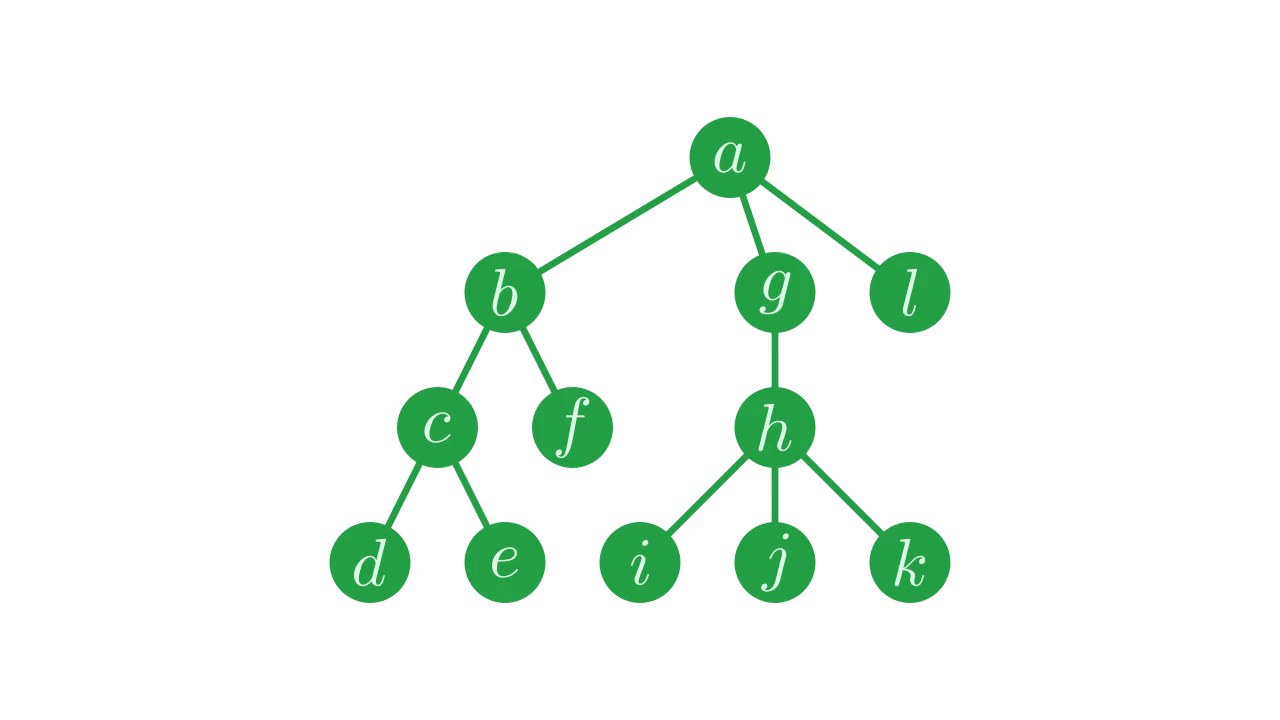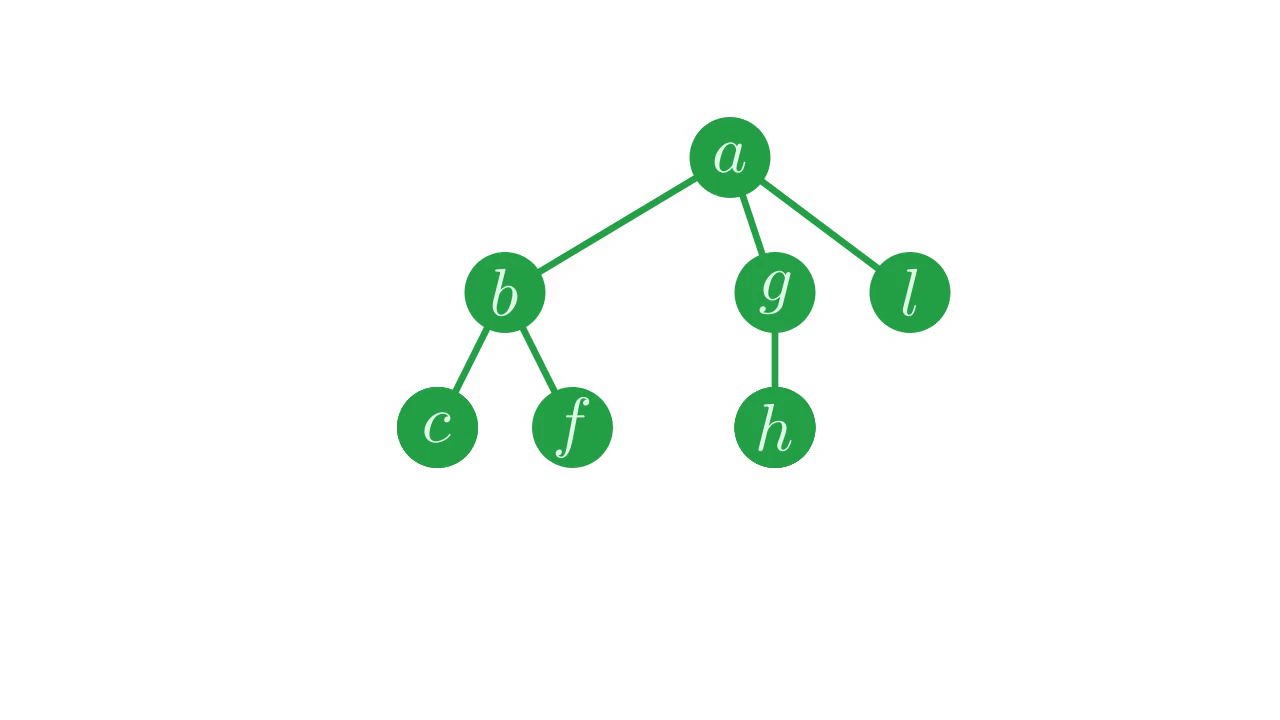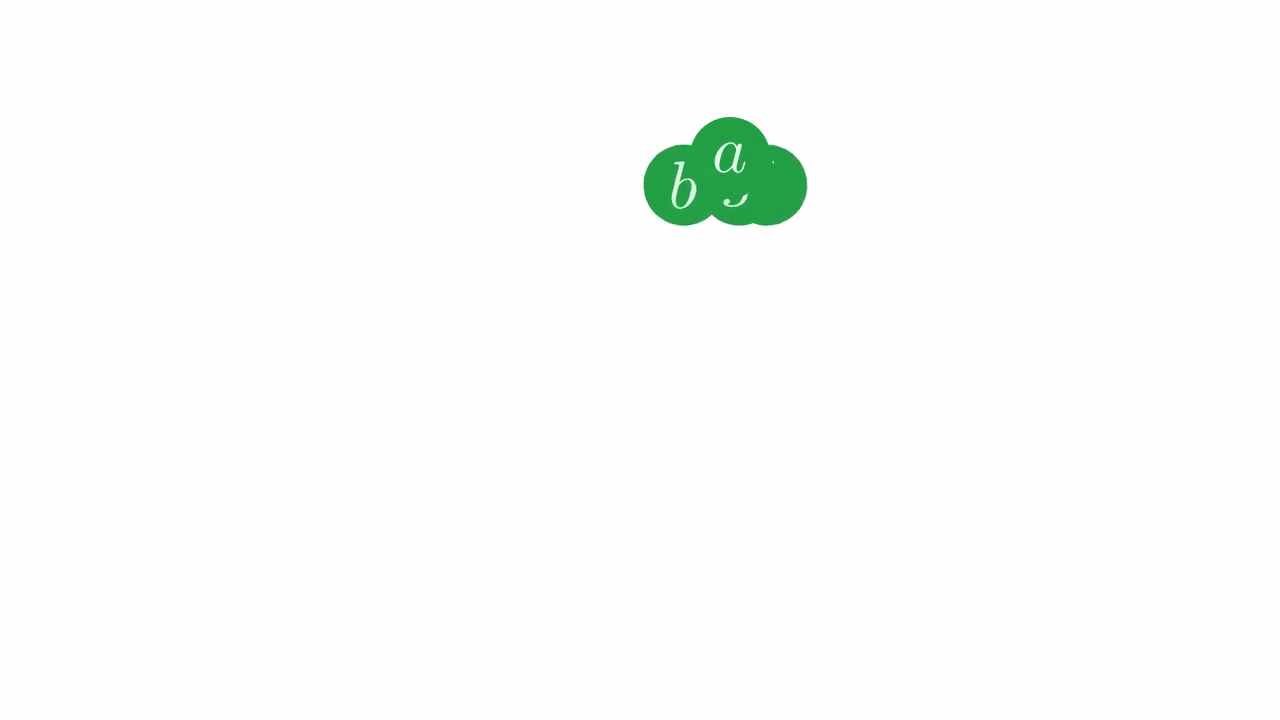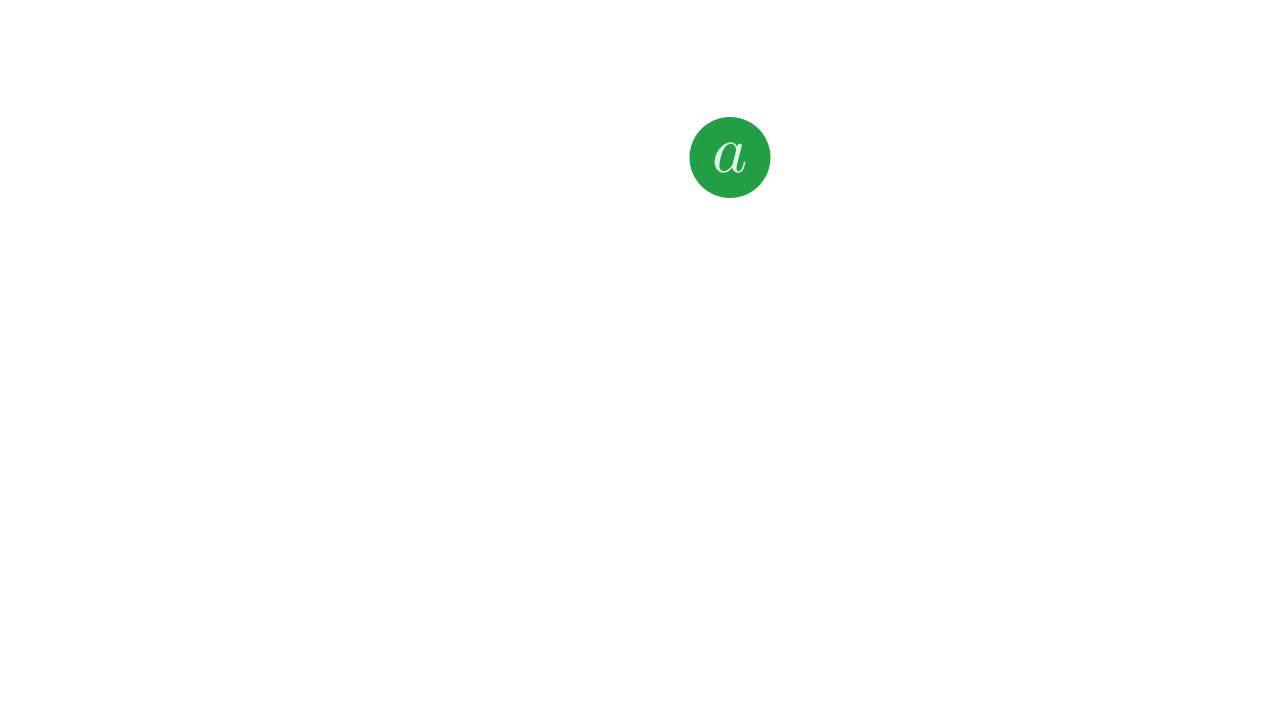
Fig. 18 How we will accumulate the nodes of the tree.#
To work from the deepest nodes upwards, we will need to know the depths of each node. Luckily for us, we know how to do that.
⍝ note that this may not be a properly ordered depth vector, but that doesn't matter for our purposes here
⊢d←Depths p
0 1 2 3 3 2 1 2 3 3 3 1
For each node, we’re going to accumulate the representation for it in a new vector r. We’re going to seed it with just the values at each node as if each node was a leaf, and then update each ancestor as we go.
⊢r←⊂¨v
┌───┬───┬───┬───┬───┬───┬───┬───┬───┬───┬───┬───┐ │┌─┐│┌─┐│┌─┐│┌─┐│┌─┐│┌─┐│┌─┐│┌─┐│┌─┐│┌─┐│┌─┐│┌─┐│ ││a│││b│││c│││d│││e│││f│││g│││h│││i│││j│││k│││l││ │└─┘│└─┘│└─┘│└─┘│└─┘│└─┘│└─┘│└─┘│└─┘│└─┘│└─┘│└─┘│ └───┴───┴───┴───┴───┴───┴───┴───┴───┴───┴───┴───┘
The maximum depth of our tree is \(3\) in this case. We’ll need to find which nodes are at this depth.
⊢i←⍸d=3
3 4 8 9 10
Next, we’ll need to group these nodes by their parent, since we only want to each node to contribute to the representation of its parent, and no other nodes which happen to be on the same level.
p[i]{⍺⍵}⌸i
┌─┬──────┐ │2│3 4 │ ├─┼──────┤ │7│8 9 10│ └─┴──────┘
For each of these groups of children, we now need to append their representations to the representation of their particular parent.
p[i]{⊂(⊃r[⍺]),r[⍵]}⌸i
┌───────────┬───────────────┐ │┌─┬───┬───┐│┌─┬───┬───┬───┐│ ││c│┌─┐│┌─┐│││h│┌─┐│┌─┐│┌─┐││ ││ ││d│││e││││ ││i│││j│││k│││ ││ │└─┘│└─┘│││ │└─┘│└─┘│└─┘││ │└─┴───┴───┘│└─┴───┴───┴───┘│ └───────────┴───────────────┘
Finally, we store this in r, and we are ready to proceed to the next level up the tree.
_←p[i]{r[⍺],←⊂r[⍵]}⌸i
r
┌───┬───┬───────────┬───┬───┬───┬───┬───────────────┬───┬───┬───┬───┐ │┌─┐│┌─┐│┌─┬───┬───┐│┌─┐│┌─┐│┌─┐│┌─┐│┌─┬───┬───┬───┐│┌─┐│┌─┐│┌─┐│┌─┐│ ││a│││b│││c│┌─┐│┌─┐│││d│││e│││f│││g│││h│┌─┐│┌─┐│┌─┐│││i│││j│││k│││l││ │└─┘│└─┘││ ││d│││e│││└─┘│└─┘│└─┘│└─┘││ ││i│││j│││k│││└─┘│└─┘│└─┘│└─┘│ │ │ ││ │└─┘│└─┘││ │ │ │ ││ │└─┘│└─┘│└─┘││ │ │ │ │ │ │ │└─┴───┴───┘│ │ │ │ │└─┴───┴───┴───┘│ │ │ │ │ └───┴───┴───────────┴───┴───┴───┴───┴───────────────┴───┴───┴───┴───┘
To run this over the entire tree, we first generate the depths of each level we need to visit, from the bottom up.
r←⊂¨v ⍝ reset r
⌽1+⍳⌈/d
3 2 1
We can then repeat our process for each level.
DoLayer←{
i←⍸d=⍵
p[i]{r[⍺],←⊂r[⍵]}⌸i
}
DoLayer¨⌽1+⍳⌈/d
Now, r contains the representation for every node in the tree.
⍪r
┌───────────────────────────────────────────────┐ │┌─┬───────────────────┬───────────────────┬───┐│ ││a│┌─┬───────────┬───┐│┌─┬───────────────┐│┌─┐││ ││ ││b│┌─┬───┬───┐│┌─┐│││g│┌─┬───┬───┬───┐│││l│││ ││ ││ ││c│┌─┐│┌─┐│││f││││ ││h│┌─┐│┌─┐│┌─┐│││└─┘││ ││ ││ ││ ││d│││e│││└─┘│││ ││ ││i│││j│││k││││ ││ ││ ││ ││ │└─┘│└─┘││ │││ ││ │└─┘│└─┘│└─┘│││ ││ ││ ││ │└─┴───┴───┘│ │││ │└─┴───┴───┴───┘││ ││ ││ │└─┴───────────┴───┘│└─┴───────────────┘│ ││ │└─┴───────────────────┴───────────────────┴───┘│ ├───────────────────────────────────────────────┤ │┌─┬───────────┬───┐ │ ││b│┌─┬───┬───┐│┌─┐│ │ ││ ││c│┌─┐│┌─┐│││f││ │ ││ ││ ││d│││e│││└─┘│ │ ││ ││ │└─┘│└─┘││ │ │ ││ │└─┴───┴───┘│ │ │ │└─┴───────────┴───┘ │ ├───────────────────────────────────────────────┤ │┌─┬───┬───┐ │ ││c│┌─┐│┌─┐│ │ ││ ││d│││e││ │ ││ │└─┘│└─┘│ │ │└─┴───┴───┘ │ ├───────────────────────────────────────────────┤ │┌─┐ │ ││d│ │ │└─┘ │ ├───────────────────────────────────────────────┤ │┌─┐ │ ││e│ │ │└─┘ │ ├───────────────────────────────────────────────┤ │┌─┐ │ ││f│ │ │└─┘ │ ├───────────────────────────────────────────────┤ │┌─┬───────────────┐ │ ││g│┌─┬───┬───┬───┐│ │ ││ ││h│┌─┐│┌─┐│┌─┐││ │ ││ ││ ││i│││j│││k│││ │ ││ ││ │└─┘│└─┘│└─┘││ │ ││ │└─┴───┴───┴───┘│ │ │└─┴───────────────┘ │ ├───────────────────────────────────────────────┤ │┌─┬───┬───┬───┐ │ ││h│┌─┐│┌─┐│┌─┐│ │ ││ ││i│││j│││k││ │ ││ │└─┘│└─┘│└─┘│ │ │└─┴───┴───┴───┘ │ ├───────────────────────────────────────────────┤ │┌─┐ │ ││i│ │ │└─┘ │ ├───────────────────────────────────────────────┤ │┌─┐ │ ││j│ │ │└─┘ │ ├───────────────────────────────────────────────┤ │┌─┐ │ ││k│ │ │└─┘ │ ├───────────────────────────────────────────────┤ │┌─┐ │ ││l│ │ │└─┘ │ └───────────────────────────────────────────────┘
The final step is to extract the representation of just the root node (or nodes, in the case of a forest).
(p=⍳≢p)/r
┌───────────────────────────────────────────────┐ │┌─┬───────────────────┬───────────────────┬───┐│ ││a│┌─┬───────────┬───┐│┌─┬───────────────┐│┌─┐││ ││ ││b│┌─┬───┬───┐│┌─┐│││g│┌─┬───┬───┬───┐│││l│││ ││ ││ ││c│┌─┐│┌─┐│││f││││ ││h│┌─┐│┌─┐│┌─┐│││└─┘││ ││ ││ ││ ││d│││e│││└─┘│││ ││ ││i│││j│││k││││ ││ ││ ││ ││ │└─┘│└─┘││ │││ ││ │└─┘│└─┘│└─┘│││ ││ ││ ││ │└─┴───┴───┘│ │││ │└─┴───┴───┴───┘││ ││ ││ │└─┴───────────┴───┘│└─┴───────────────┘│ ││ │└─┴───────────────────┴───────────────────┴───┘│ └───────────────────────────────────────────────┘
And we are done! This is the general format for accumulating values according to a tree. Indeed, look back at _PrettyPrint_ - it uses exactly this method.
Putting this together into a dfn, there’s one more thing we need to worry about. When we have a tree or forest consisting of only root nodes, that is, all nodes have depth \(0\), our ¨ will still run once on the prototype of ⌽1+⍳⌈/d, leading to an incorrect result. Therefore, we will introduce a guard statement to avoid this.
ParentToNested←{ ⍝ convert a parent vector to a nested representation
p←⍵ ⍝ input parent vector
⍺←⊂⍤,¨⍳≢p
r←⍺ ⍝ values to place at nodes (by default, their indices in the parent vector)
d←Depths p
maxDepth←⌈/d
maxDepth=0: r
DoLayer←{
i←⍸d=⍵
_←p[i]{r[⍺],←⊂r[⍵]}⌸i
1 ⍝ the interpreter will complain if we don't provide a result
}
_←DoLayer¨⌽1+⍳maxDepth
(p=⍳≢p)/r
}
v ParentToNested p
┌─────────────────────────────────┐ │┌─┬─────────────┬─────────────┬─┐│ ││a│┌─┬───────┬─┐│┌─┬─────────┐│l││ ││ ││b│┌─┬─┬─┐│f│││g│┌─┬─┬─┬─┐││ ││ ││ ││ ││c│d│e││ │││ ││h│i│j│k│││ ││ ││ ││ │└─┴─┴─┘│ │││ │└─┴─┴─┴─┘││ ││ ││ │└─┴───────┴─┘│└─┴─────────┘│ ││ │└─┴─────────────┴─────────────┴─┘│ └─────────────────────────────────┘
We should mention that, for simple accumulations, it’s also possible to forego using ⌸, and instead simply use indexing. For instance, we could also have written our accumulation like so:
r←⊂¨v
DoLayer←{
i←⍸d=⍵
r[p[i]],←⊂¨r[i] ⍝ using indexing instead of ⌸
1
}
_←DoLayer¨⌽1+⍳⌈/d
(p=⍳≢p)/r
┌───────────────────────────────────────────────┐ │┌─┬───────────────────┬───────────────────┬───┐│ ││a│┌─┬───────────┬───┐│┌─┬───────────────┐│┌─┐││ ││ ││b│┌─┬───┬───┐│┌─┐│││g│┌─┬───┬───┬───┐│││l│││ ││ ││ ││c│┌─┐│┌─┐│││f││││ ││h│┌─┐│┌─┐│┌─┐│││└─┘││ ││ ││ ││ ││d│││e│││└─┘│││ ││ ││i│││j│││k││││ ││ ││ ││ ││ │└─┘│└─┘││ │││ ││ │└─┘│└─┘│└─┘│││ ││ ││ ││ │└─┴───┴───┘│ │││ │└─┴───┴───┴───┘││ ││ ││ │└─┴───────────┴───┘│└─┴───────────────┘│ ││ │└─┴───────────────────┴───────────────────┴───┘│ └───────────────────────────────────────────────┘
Here, we exploit that fact that indexed assignment (r[p[i]],←) gracefully handles repeated indices. When p[i] gives repeated parents (which it often will, as parent nodes rarely have just one child), the catenations each happen in turn.
Challenges#
Challenge 1: Given a forest, and a vector of numbers associated with the nodes, find the sum of each tree in the forest. To check your solution, make sure that the sum of the values for each tree equals the overall sum of the data.
Solution:
Show code cell content
Sum←{ ⍝ sum the values in each tree in a forest
v←⍺ ⍝ numbers at each node
p←⍵ ⍝ parent vector
sums←v
d←Depths p
maxDepth←⌈/d
maxDepth=0: sums
DoLayer←{
i←⍸d=⍵
sums[p[i]]+←sums[i]
1
}
_←DoLayer¨⌽1+⍳maxDepth
(p=⍳≢p)/sums
}
Challenge 2 (bonus): Do the same thing, but without using the template we described on this page.
Solution:
Show code cell content
⍝ this exploits the commutativity of addition
Sum2←{(I⍣≡⍨⍵)+/⍤⊢⌸⍺}
Challenge 3: Given a tree, find the height of each node. The height of a node is its depth subtracted from the depth of the node’s deepest descendant.
Solution:
Show code cell content
Height←{ ⍝ find the height of each node in a parent vector
p←⍵ ⍝ parent vector
heights←0⍴⍨≢p
d←Depths p
maxDepth←⌈/d
maxDepth=0: heights
DoLayer←{
i←⍸d=⍵
p[i]{heights[⍺]←1+⌈/heights[⍵]}⌸i
1
}
_←DoLayer¨⌽1+⍳maxDepth
heights
}